Sending async data from Rails into the world (II)
… and check why 5600+ Rails engineers read also this
Sending async data from Rails into the world (II)
In this series of blog posts we discuss possible implementation options for sending data asynchronously from Rails applications. The two common use cases involve delivering exceptions and business metrics to external services.
The second part describes another two solutions: using Thin and classic threads. Read the first part if you have not done it yet.
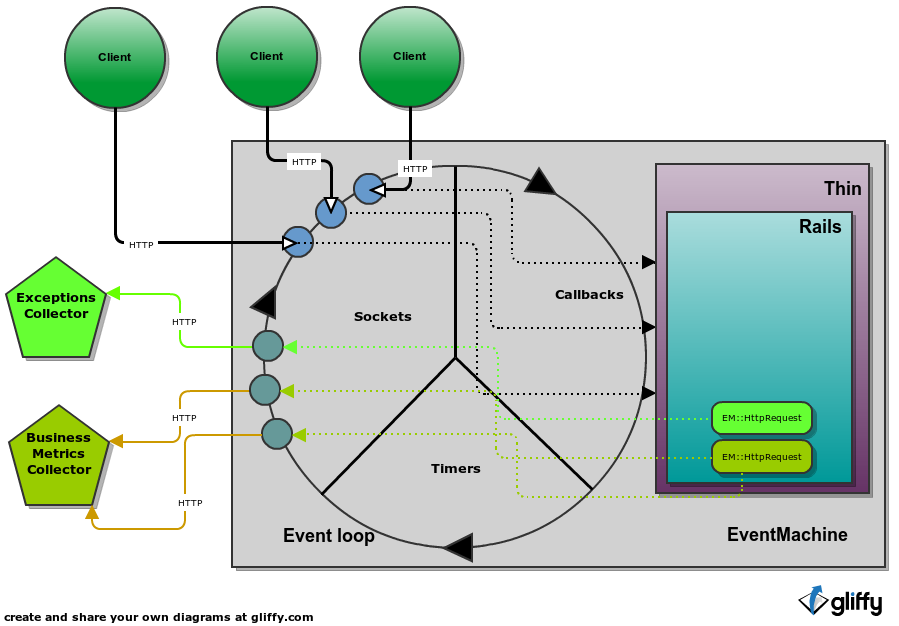
Thin / Event Machine
One of the option that we have is to utilize the power of underlying web server. This might be possible if you are using Thin for running your web application which is built on top of EventMachine (watch the peepcode EM screencasts if your are interested) event-processing library. EM is already built with asynchronicity in mind and uses classic reactor pattern involving event loop which you might know from projects such as Nginx or HAProxy.
For sending async http request we must use dedicated library that supports it. The de facto standard in EM world is em-http-request. When HTTP request is issued inside our Rails application during request handling we don’t wait for the result, rather fire-and-forget. After all remaining http requests are handled the loop continues working. It is now time to asynchronously send outgoing request that was scheduled and process data from incoming sockets. The cycle continues forever until application is stopped.
If you are already using Thin, which is built on top of EM, sending such data without blocking your Rails application is trivial. Just embrace the features of your webserver.
The good parts
- Usage of existing infrastructure
- Capability of handling huge amount of outgoing data. Useful if customers want to send business metrics frequently.
- Timers can be used to easily implement exponential backoff. Just schedule retry in X seconds if data delivery failed.
Problems
- Solution available only to small amount of Rails developers. As owner of a product that is supposed to receive data from clients you cannot (nor want to) force your customers to use specific webserver which might simply not be the best fit for their needs.
- If you start implementing things such as exponential backoff based on EventMachine framework you might end up with a process which has two responsibilities. Not only it manages your http requests but also needs to deliver errors, trace timeouts, schedule exponential retries, log them and what not. And that’s like having two applications in one process. Bad idea usually.
Summary
If you would like your customers that use Thin webserver to send you data it might be just enough to specify the protocol properly. Likely they can handle sending you data asynchronously themselves simply by using em-http-request library. Those using EventMachine are already well familiar with it. So just don’t make the job for them harder :)
Threads with Queue
Probably one of the most obvious solution is to use bunch of threads and delegate the job of sending data to them.
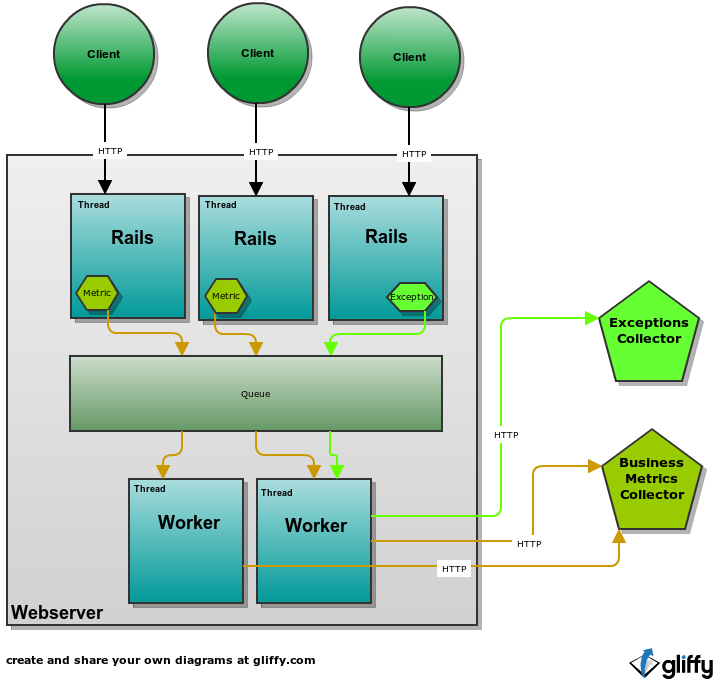
We can have multiple threads processing HTTP requests (probably spawned by our webserver such as Puma) or one main thread doing that (as in Unicorn). The diagram shows multiple threads but that does not matter. Whether you need more or less workers compared to Rails threads depends on number of external requests that you need to perform and how long they take. You might need small number for sending exceptions but big number for sending metrics. YMMV.
For sharing the jobs between Rails and worker threads you can use standard
Ruby Queue
(remember to require 'thread') which is already threadsafe.
But if you feel brave you can instead use
PUSH/PULL
ZMQ sockets with
inproc transport.
Good parts
- Simple to use and implement
- Familiar to most developers
- Reasonable to use in most webservers (multi or single-threaded)
Problems
- No easy solution that would prevent queue overflow. When worker threads are not performing well enough (possibly due to network issues) or we spawned too little of them the queue size might keep growing. The solution would be to have min and max number of possible worker threads and create/destroy them depending of queue size. That is however a tedious work.
- When the webserver or application is being stopped/restarted there still might
be queued jobs. You might try to send them if your webserver provides hook that
is executed when the application is being stopped. When no such hook is available
you might need to resort to implementing such logic in
at_exithook. However its execution depends on the signal that was used to finish the process. It works whenTERMwas used but not whenKILL(obviously).
Summary
This is probably best approach for a gem that your customers need to include in their app to automatically send you some kind of data (such as exceptions). More advanced customers can always roll out their own solution based on your API. Mainstream expects you to provide something easy, working and not interfering with their app too much. When you have that, you can focus on supporting more sophisticated features and distribution architectures.
Tell me more
Stay tunned for the next episodes. Follow us on twitter
or subscribe to RSS feed so you do not miss it. In the last episode I am going
to cover Rails.queue which will be released in the upcoming Rails 4 version
as well as using external queues. Also I want to write a simple summary of all
approaches that will help you visualize them as variants of one simple pattern.