Sending async data from Rails into the world
… and check why 5600+ Rails engineers read also this
Sending async data from Rails into the world
Exceptions and business metrics. These are two common use cases involving delivery of data from our Rails application (or any other web application) to external services that are not so crucial and probably we would like to send them asynchronously instead of waiting for the response, blocking the thread. We will try to balance speed and certainty here, which is always a hard thing to achieve.
This is a series of posts which describe what techniques can be used in such situation. The first solution that I would like to describe (or discredit) is ZMQ.
ZMQ - the holy grail of messaging
What is ZMQ ? According to the lengthy and funny ZMQ guide:
ØMQ (ZeroMQ, 0MQ, zmq) looks like an embeddable networking library but acts like a concurrency framework. It gives you sockets that carry atomic messages across various transports like in-process, inter-process, TCP, and multicast. You can connect sockets N-to-N with patterns like fanout, pub-sub, task distribution, and request-reply. It’s fast enough to be the fabric for clustered products. Its asynchronous I/O model gives you scalable multicore applications, built as asynchronous message-processing tasks. It has a score of language APIs and runs on most operating systems. ØMQ is from iMatix and is LGPLv3 open source.
You can also watch an introduction to ZMQ delivered by one of the creators of this library: Martin Sustrik: ØMQ - A way towards fully distributed architectures
It seems like a perfect candidate at first sight, so let’s dive into this topic a little bit.
How would that work ?
I believe that we could use diagram here.
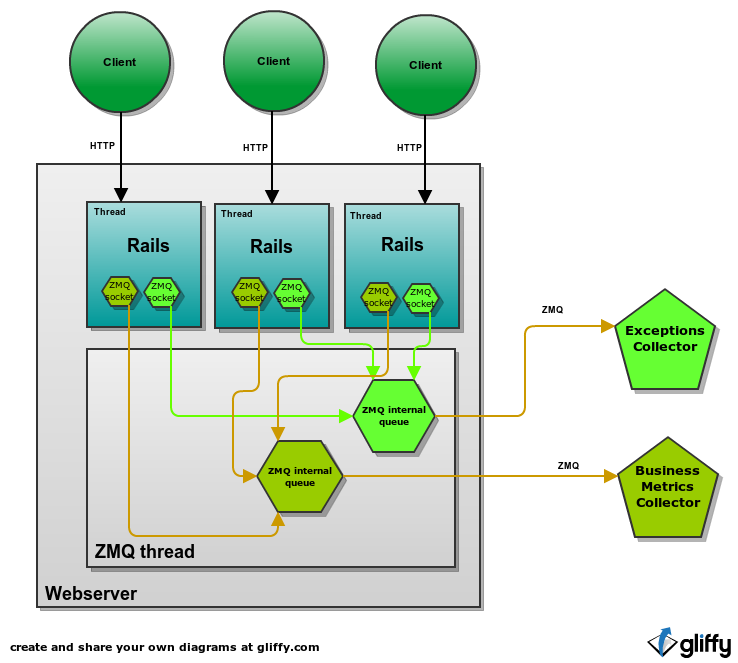
Every rails thread (I assume multithreading app here, but it does not matter a lot) would have a ZMQ socket for sending exceptions and business metrics. Sending a message with such socket means only that it was delivered to ZMQ thread which will try to deliver it further.
The good parts
- Async. The Rails app can use async interface to ZMQ and never block for sending message. However it means that some messages might be dropped in case of special condition like lack of connection or overflow. It might also use sync interface and block when there is a problem but this is not what we are trying to achieve now. We want exactly the contrary :)
- ZMQ is capable of dropping messages when one of the side is not performing well enough
- ZMQ can be configured to try to deliver unsent messages in X seconds when process is being closed. That could be useful but it would require your webserver to expose hook for such event, so that you can tell ZMQ to shut down when webserver is shutting down. I am not sure if every popular webserver used in Ruby community exposes such API.
- Capable of using exponential backoff strategy for reconnects (although by default uses static intervals).
Problem ?
- ZMQ probably works best when compiled from source. We had problems with the version provided in debian packages when using ZMQ from Mongrel2 (M2 issue, Arch issue ). People generally do not like doing that and for some reason are scared of it.
- Although ZMQ is getting more and more popular, people are still not familiar with it. And we tend to avoid what we don’t know. But I encourage you to get out of your comfort zone and meet ZMQ.
- ZMQ will not retry sending undelivered messages.
- ZMQ was not designed to be exposed to wild world. It would probably require the external service to provide a separate endpoint (meaning at least different port for tcp connection) for every client.
- Asymmetric encryption is not straightforward
Summary
- Seems like a really good fit for non-critical data that might rarely get dropped.
- Fantastic for internal usage, terrible for external.
- Not for newbies.
- Lack of simple encrypted transport for ZMQ.
So …
If you are building a solution and would like your customers to send you some data from their applications, ZMQ is probably not the way to go.
Separate process
Another common way of solving this problem is to have separate process which your application communicate to. That process receives events from your app and sends them further to the external service.
Architecture
Let’s see a diagram:
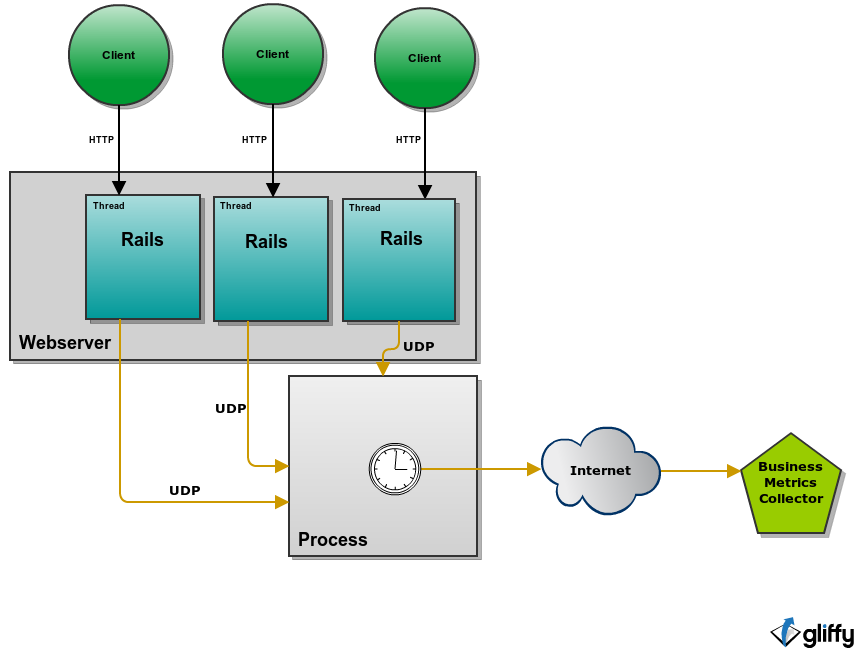
Rails application can communicate with the process running in customer infrastructure using any protocol it wants. That could be for example ZMQ or UDP if we value simplicity. That process is then responsible for delivery of events to the external service. This is a common pattern in business metrics solutions. Application can send huge number of events to the process who is responsible for aggregation and periodically sends aggregated data further.
There could be benefits of using such architecture for exception delivery. The middle process is a very good candidate to put in the responsibility of doing retries with exponential backoff strategy.
The good parts
- Rails application can use UDP to asynchronously send data to the middle process which is still in the same network infrastructure so it has very high probability of being delivered.
- The middle process can be responsible for retries.
- No problem of lost messages when Rails app is restarted during deploy because messages are kept in a separate long-living process which is not restarted.
- Communication between middle process and external web service can use a different, more reliable protocol such as HTTP.
Problems
- One more process to manage and monitor
- Some cloud solutions charge additional fees for such separate process.
Summary
- Because of the additional burden related to having a separate process this would be a good strategy that we could recommend for semi advanced customers. Those who do not feel the Fear of adding processes or at least are capable of overcoming it.
Tell me more
Stay tunned for the next episodes. Follow us on twitter or subscribe to RSS feed so you do not miss it.