Using influxdb with ruby
… and check why 5600+ Rails engineers read also this
Using influxdb with ruby
InfluxDB is an open-source time series database, written in Go. It is optimized for fast, high-availability storage and retrieval of time series data in fields such as operations monitoring, application metrics, and real-time analytics.
We use it in chillout for storing business and performance metrics sent by our collector.
InfluxDB storage engine looks very similar to a LSM Tree. It has a write ahead log and a collection of read-only data files which are similar in concept to SSTables in an LSM Tree. TSM files contain sorted, compressed series data.
If you wonder how it works I can provide you a very quick tour based on the The InfluxDB Storage Engine documentation and what I’ve learnt from a Data Structures that Power your DB part in Designing Data Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
First, arriving data is written to a WAL (Write Ahead Log). The WAL is a write-optimized storage format that allows for writes to be durable, but not easily queryable. Writes to the WAL are appended to segments of a fixed size.
The WAL is organized as a bunch of files that look like _000001.wal. The file numbers are monotonically increasing and referred to as WAL segments. When a segment reaches a certain size, it is closed and a new one is opened.
The database has an in-memory cache of all the data written to WAL. In a case of a crash and restart this cache is recreated from scratch based on the data written to WAL file.
When a write comes it is written to a WAL file, synced and added to an in-memory index.
From time to time (based on both size and time interval) the cache of latest data is snapshotted to disc (as Time-Structured Merge Tree File).
The DB also needs to clear the in-memory cache and can clear WAL file.
The structure of these TSM files looks very similar to an SSTable in LevelDB or other LSM Tree variants.
In the background, these files can be compacted and merged together to form bigger files.
The documentation has a nice historical overview how previous versions of InfluxDB tried to use LevelDB and BoltDB as underlying engines but it was not enough for the most demanding scenarios.
I must admin that I never really understood very deeply how DBs work under the hood and what are the differences between them (from the point of underlying technology and design, not from the point of APIs, query languages, and features).
The book that I mentioned Designing Data Intensive Applications really helped me understand it.
Let’s go back to using InfluxDB in Ruby.
influxdb-ruby gem
For me personally, influxdb-ruby gem seems to just work.
writes
require 'influxdb'
influxdb = InfluxDB::Client.new
influxdb.write_point(, {
series: 'orders',
values: {
started: 1,
number_of_products: 4,
total_amount: 55.70,
tax: 5.70,
},
tags: {
country: "USA",
terminal: "KATE-123",
}
})
The difference between tags and values is that tags are always automatically indexed.
Queries that use field values as filters must scan all values that match the other conditions in the query. As a result, those queries are not performant relative to queries on tags.
reads
However, InfluxQL query language (similar to SQL but not really it) really shines when it comes to returning data grouped by time periods (notice GROUP BY time(1d)), which is great for metrics and visualizing.
raw data using influxdb console
SELECT
sum(completed)/sum(started) AS ratio
FROM orders
WHERE time >= '2017-07-05T00:00:00Z'
GROUP BY time(1d)
name: orders
time ratio
---- -----
1499212800000000000 0.8
1499299200000000000 0.7
1499385600000000000 0.6
where Time.at(1499212800).utc is 2017-07-05 00:00:00 UTC and
Time.at(1499299200).utc is 2017-07-06 00:00:00 UTC.
influxdb-ruby
Using the gem you can easily query for the data using InfluxQL and get these values nicely formatted.
influxdb.query "select sum(completed)/sum(created) as ratio FROM orders WHERE time >= '2017-07-05T00:00:00Z' group by time(1d)"
[{
"name"=>"orders",
"tags"=>nil,
"values"=>[
{"time"=>"2017-07-05T00:00:00Z", "ratio"=>0.8},
{"time"=>"2017-07-06T00:00:00Z", "ratio"=>0.7},
{"time"=>"2017-07-07T00:00:00Z", "ratio"=>0.6}
]
}]
What for?
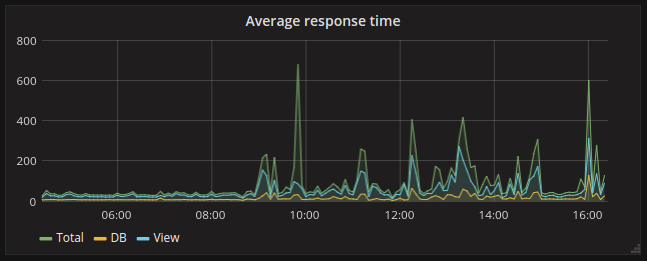
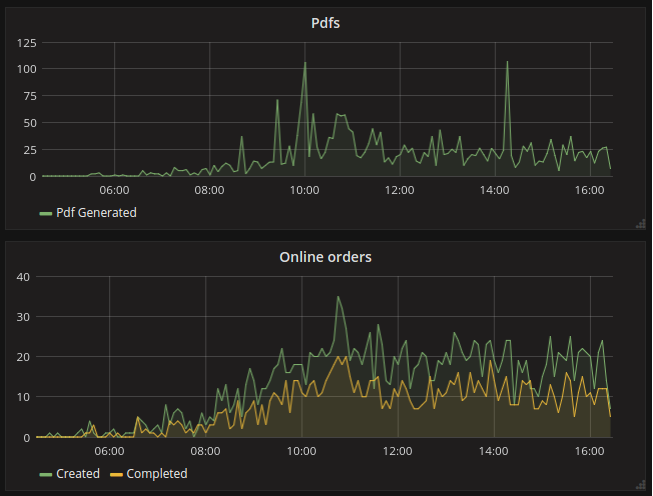
For dashboards and graphs, monitoring and alerting. For business metrics:
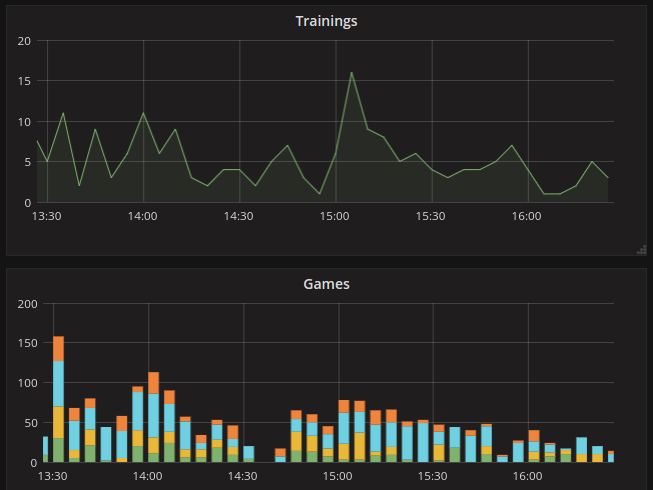
And performance metrics (monitoring http and sidekiq):